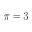Das hier ist eine π=3 Wasserstandssmeldung und kleine Werbung für den Eigenraum-Podcast, den ihr unter diesen Koordinaten findet:
- Web: https://eigenpod.de
- RSS: https://eigenpod.de/feed/mp3
- Mastodon: @Eigenraum@podcasts.social
Viele Grüße aus Magdeburg.